
SRE座談会
はてなのSREが語る、チームを横断した標準化活動と働き方
はてなでは、さまざまなチームのSRE(Site Reliability Engineer)が横断的に集まり、技術的な標準化を通じて社内の各チームのSREを支える活動を行っています。チームごとの具体的な取り組みについて、CTOのid:motemenと、SREのid:masayosu、id:taxintt、id:cohalzの3人に語ってもらいました。
はてなのSREが取り組む社内技術の標準化とは
まずはみなさんの自己紹介、チームでの役割を教えてください。
サービスプラットフォームチームのEmbedded SREとして、現在はAmazon EKSのチームでの運用をメインに担当しています。
はてなのサーバー監視サービス「Mackerel」の開発チームでEmbedded SREとして働いています。最近は、EC2で動いてるProxyサーバーのECS化をしていました。
はてなブックマークの開発チームでEmbedded SREをやっています。1年前までは、はてなブログの開発チームでSREをやっていました。最近はDBのアップグレードやAWSのアカウント移行などを担当しています。
はてなのCTOとして、エンジニア職種グループのマネジメントや全社の技術的な方針・方向性を考える役割を担っています。今回の座談会では、はてなの技術の標準化を担当しているSREのメンバーに、現場での具体的な取り組みについて語ってもらいたいと思っています。よろしくお願いいたします。
はてなの技術に対する標準化を始めた背景・理由を聞かせてください。
はてなのSREには、Embedded SREとPlatform SREという大きく2つのポジションがあります。Embedded SREは開発チームの中に入って、開発チームのプロダクトの安定性や開発チームの生産性に貢献する役割を担っています。一方、Platform SREは各サービスで利用されるインフラの足場を整え、推進する役割です。

はてなの初期は自社toCサービスの一事業だった経緯もあり、インフラやアプリケーション実行基盤は一枚岩で構成されていて、それをメンテナンスする専任のチームを置いていました。その後現在のように事業が多角化していき、すべてのサービスが同じ基盤に乗るのは開発・運用の面でさまざまな不都合があるというわけで、インフラも含めて開発チームがプロダクト全体のオーナーシップを持つように体制を変えていきました。 すると当然ながら、各チームが使う技術やノウハウがばらばらになっていったんですよね。ここで事業をサイロ化させていくことは、はてなの職能組織として本意ではない、ということでチーム横断的に技術を標準化していく取り組みを始めることになりました。
その中でもSREが担当する領域は、SREの社内における横の繋がりを活かして、高い具体性を持って共通化できる領域だと思っています。サービスで利用するミドルウェアや、IaC(Infrastructure as Code)化されたインフラのコードレベルでの共有などですね。今回はid:cohalz、id:masayosu、id:taxinttに、実際にSREが今どんなことをやっているのかを語ってもらいたいと思います。
ECSによるデプロイフローの標準化、CI/CDの標準化の舞台裏
cohalzさんが担当するECSによるデプロイフローの標準化、CI/CDの標準化について、プロジェクト概要やどのような課題を解決しようとしているのか聞かせてください。
先ほどのmotemenさんの説明にもあったように、はてなはもともと同じ基盤の上にサービスを構築していましたが、最近はサービスのコンテナ化やCI/CDをそれぞれの開発チームが独立して設計し、実施するようになっていきました。
チームによってアプリケーションのデプロイ方法が違うため、他チームのいいやり方を取り入れるコストや異動時のキャッチアップコストが高い状態でした。そこで現在は各チームのデプロイフローを標準化し、開発スピードを上げたり学習コストを下げるための取り組みが進んでいます。
利用している技術はプロダクトによって違うものの、コンテナ化を進めていたおかげで、アプリケーションとインフラがうまく分離して、「標準的なデプロイフロー」を適用しやすくなりましたね。
具体的にはどういう技術を使って作っていったのでしょうか。
GitHub Actionsをベースに、CI/CDを作っています。ツールとしてはecspressoを使ってデプロイを行っています。GitHub Actions上でecspressoのコマンドを実行してデプロイするため、手元からは実行しない仕組みです。
独自のかっこいい仕組みを内製するのではなく、基本的に世の中に広く使われたいいものを取り入れていくというスタンスですね。
そうです。CloudNative推進会という社内のコンテナ化をサポートするワーキンググループを作って、CloudNative CI/CDについて考えたり、それをECSで実現した実例などもあります。
そもそもCloudNative CI/CDをまとめようと思った経緯は何ですか?
Cloud Native Trail Mapを参考に、コンテナ化以後のより良いCI/CDを定義することを目的としたドキュメントを以前に作っていました。
そのドキュメントを元に各チームが実装する場合、実装コストもかかりますし実装後の構成も各チームで似通ったものになります。
そうした実装コストの削減や、各チームの細かい部分の差異でハマらないようにドキュメントだけでなく標準化したCI/CDの実装を提供するという形を取るようにしたという感じです。
このCloudNative CI/CDの実装を他のチームにシェアする移行用のツールも結構作りましたね。GitHub ActionsのReusable workflowやリリース用のテンプレートリポジトリなどを作っています。
CI/CDの構築をする際にecspressoを使い設定を細かくディレクトリ分割しているのですが、ecspresso単体ではディレクトリを分ける作業が大変なので、ファイルを適切にディレクトリに分けて置いてくれるツールも作りました。
こういったツールを使うことで作成したCI/CDのフローを簡単にいろんなチームで導入できるようになっています。
これらのツールを社内のSRE標準化委員会で更新していくのですが、新しい機能を追加するときにRenovateを使うとGitHub Actionsのバージョン管理で更新してくれるんですね。変更内容もRenovateがリリースノートに書いてくれるので、古びない仕組み作りと合わせて考えています。
古びない仕組みを作ることは重要ですね。はてながワンプラットフォームだった頃は、社内モジュールや社内ライブラリを共有してコードを使っていたけど、自分たちのチームで使いやすいように共有モジュールをフォークしていったのをうまく合流させられずに、各チームでコードがバラバラになってしまった。
そうなると、遺伝子のルーツは一緒なのにそれぞれの進化を取り入れることができなくなってしまうので、きちんとアップストリームに還元していくということですね。それが伝播していく仕組みを、オープンなツールをベースにして作るようになったのはいい変化ですね。今どきのオープンソース開発の良さを取り入れていることは、今やっている標準化のポイントだと思います。
ちなみに、これらの標準をどのように社内に広めていったのでしょうか。
まずコンテナ化を進めているチームを中心に、どのような課題があるか、CI/CDをどう動かしているかについてヒアリングをしました。それをもとにどのチームでも使えるものは何かを考えていきました。
コンテナ化は最初にブログチームがプロトタイプを作っていたので、そのプロトタイプをもとにMackerelチームとブックマークチームが改良してコンテナ化しました。2チームできちんと動いたものをブラッシュアップして全社に展開する進め方ですね。
Mackerelチームの中でも、標準化されたデプロイフローを展開する動きがあります。例えば、最近実施したProxyサーバーのECS化でも標準化された構成を利用しています。一から考えていくと設計・実装含めて大分かかるコストが標準化することで省力化ができたので、メリットを享受できている印象があります。
標準って、頑張って作っても実際に使ってもらえなかったら意味がないので、ブログとMackerelという性質の違うプロダクトに対して適用できたことを確認して、社内展開できたことは意味のあるプロジェクトだと言えますね。
ecspressoにコントリビュートしているという話を聞きました。
ブログチームでコンテナ移行をしていく上で、社内利用にいろいろ足りない機能があったので、Pull Requestを作りまくりました。CodeDeployのロールバックを使えるようにしたりとかですね。ecspressoはTerraformと連携できるので、Terraform Cloudを使って連携できるようにもしました。
広く使われているツールの上で自分たちが使いやすいフローを構築するために、OSSに還元していく、という動きが取れているのは理想的だなと思います。全社的にお世話になっているので、ecspressoへの寄付も行ったところですね。
ECSの標準化から、EKSの標準化に向けた新たな取り組み
ECSの標準化は実際に複数のチームに浸透していますが、EKSの標準化については、まさにこれからという段階だと思います。EKS標準化に取り組むことになった経緯や目的について聞かせてください。
EKSの標準化を進めた背景は、これからEKSを利用したいチームが出てきたときに備えて、標準構成を作って、その知見を社内で共有し、スムーズに導入できるようにするためです。
僕が所属しているサービスプラットフォームチームでは、EKSを社内で先行して利用しており、実際に標準構成を使って構築をしているものがプロダクションで動いている状況です。 構築にはTerraformを利用しているので、Terraformを叩いてもらえれば、リソースが出来上がって、環境が出来上がるという状態ですね。Mackerelチームでもこの標準構成を利用して構築を進めています。
EKSの社内利用事例は少ないので、作っているものが筋の良い構成なのかどうか判断するのは難しかったのでは?
実際に運用がうまくいった事例やツールなどは、社内に広めていったのですが、知見が足りない部分もありました。その辺はKubernetes MeetupやAmazon EKSのコンテナラウンドテーブルといった社外コミュニティに相談させていただき、お勧めしてもらったものを検証しながら使っていました。
他社と話したり、アドバイスを受けたことで何か発見はありましたか?
他社は、Kubernetesのオペレーターを自作でガリガリ作っている印象を受けました。我々はメンテナンスに対応できる人数が多くなかったため、省力化での運用方法を目指していたので、そこに違いを感じましたね。今後も既に使えるものがあるのであれば、そちらを優先して使うという方針で考えています。
自分たちに合わせてカスタマイズしていくというよりは、今ある筋のいいツールなどを活用していくというのが、考え方のポイントになっています。
実装周りで何か面白いポイントはありますか?
Terraformで実装しているので、AWSのリソースを利用できるのですが、その際にKubernetesのアドオンも一緒にインストールできるようにしています。Terraformの中でHelmというKubernetesのアドオンを管理する仕組みのプロバイダを利用して、全てが構築できるように用意しています。
ちなみに、アドオンはどんなものを使っているのでしょうか。
Kubernetesのメトリクスを収集するためMetrics Serverを利用しています。またKubernetesのイベントログが一定期間しか保持できないので、それを外に出すEventexporterを使っています。
あとはNodeをスケールさせつつ、Nodeをスポットインスタンスかオンデマンドインスタンスをいろいろ利用することで、NodeをスケールすることができるKarpenter。Kubernetesはデフォルトのままではcorednsが詰まったりするようなことがあるので、そのDNSのオートスケーラーはデフォルトで入れています。
構築できるだけではなく、運用上で詰まったり困りそうなところもカバーしていますね。実際にサービスプラットフォームチームで運用してみた知見が反映されている。 社内ではEKS構築ソン(構築+ハッカソン)をしながら知見を収集していったこともありましたね。
社内にEKSやKubernetesの知見を持っている人がそもそも少なかったということがあり、標準構成を作るにあたって、まずはSREのメンバーと一部のアプリケーションエンジニアを対象にEKS構築ソンを実施しました。
Kubernetesの基本的な知見も必要となるので、クラスター構築やアドオンのリソースなどの概念やポイントの解説もあわせて行いました。
その他に、masayosuさん的に面白かったことってあります?
標準構成を考えるときに、ゾーンで分けていったんですけど、その考え方が面白かったです。CIゾーンやアーティファクトゾーン、オーケストレーターゾーン、ロギングゾーンというゾーンごとに分けて、ECSで使える技術を当てはめていったのですが、この分け方がとても上手く成功したと思っています。
EKSがどうこうという前に、まずSREが作る標準構成とは何かについて考える。標準構成の抽象的な構成図を作った上で、それをECSで実現するにはどうするか、一方でEKSで実現するにはこうだよねと検討しながら実装していったということですね。
また新しいプラットフォームツールが出てきても、標準構成に当てはめて考えていくという道はできているというのは面白いと思います。
デプロイはArgoCDというツールを使っているんですけど、これが便利で優秀なんですよ。必要なところだけ機能を取り出せるし、コンパクトで大きすぎない。ちょうどいいサイズだったりするので、CloudNative CI/CDを考えるときに、ArgoCDのベストプラクティスは結構参考にしました。
マニフェストを一つのリポジトリに集約する考え方などは、ArgoCDのベストプラクティスからCloudNative CI/CDの中に盛り込んだりしています。
過去の障害データをもとに「数字で見る障害対応」に取り組む
taxinttさんは、監視改善や障害対応などのSLO周りにおける各チームの改善を担当していますが、具体的にはどのような業務をしているのか聞かせてください。
私たちのグループでは、監視周りの改善チームと障害対応とSLO周りというサブチームに分かれています。私は後者の方に所属していて、今は「数字で見る障害対応」という障害対応の改善活動を開発チームに展開していく取り組みを行っています。
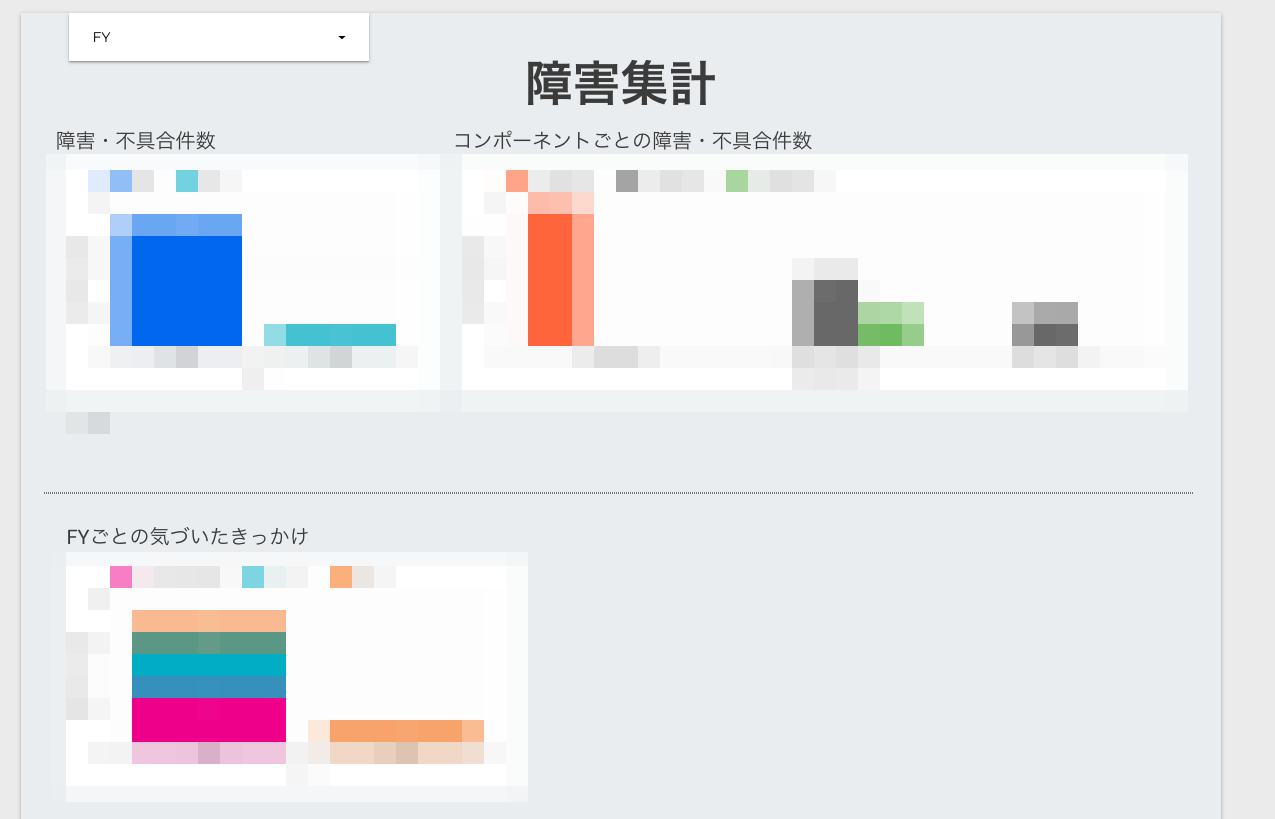
具体的には、過去何年分かの障害履歴を、コンポーネントごとの障害不具合件数、障害の発生時刻や修正された時刻、障害に気づいたきっかけ、種類・タイプなどをスプレッドシートで集計しています。その障害集計から見えてくる障害の傾向を分析して、障害対応の改善に活用しようというのが、今私たちのチームがやっていることです。
やってみて得られた示唆はありますか?
Mackerel開発チームで気づいた傾向としては、例えば障害タイプのうちバイナリプッシュ、いわゆるリリースの回数が増えていること。リリースに関連する障害が増えていると同時に、リリースの回数も増えているので、開発自体が活発になっていることがわかります。つまり、リリース回数と障害発生数には相関関係が見られました。
それ自体は問題ではないと考えています。が、一方で、発覚の理由の部分でいうと、問い合わせからの発覚が目立っています。これは自動的な検知の部分に課題があると考えており、今後はアラートでの検知の比率を高めるための対策をとっていきたいですね。
それはまさに監視の改善ですね。お客様に影響が出る前に、不具合や異常を検知して早期対処したいというモチベーションがあるわけだから。どこを改善していったらいいかを可視化することで、課題がかなり見えてくる感じがします。
バイナリプッシュで障害が発生したのであれば、ある程度相関があるだろうから、そこは比較的コントロールしやすそう。デプロイが全然増えていないのに、障害だけ増えているのであれば、何かよくないことが起きているということがわかる。状況を詳しく見ていける仕組み作りができているのはいいことだと思います。これまでの障害の記録をしっかりと残してきたことも効いていますね。
ある程度件数が残っていると傾向が見えてくるので、そこからチームとしての課題が可視化できるようになっています。SRE標準化委員会では、今Mackerelのデータだけを集計しているんですが、他のプロダクトの障害履歴のデータも含めて集計したときに、どのような傾向の違いがあるかを分析しています。
例えば、特定のプロダクト開発チームは障害復旧までの時間が他チームと比べて短い場合、「障害対応のフローが整備されている」「障害対応のフロー自体がスムーズに進んでいる」といったことが仮説として導き出される。それをもとにヒアリングを行ったり、チームをまたいだ改善施策の検討など、次のアクションにも繋げられると考えています。
教育や情報共有のためには、障害対応している様子をリアルタイムで見ることができたらいいんだけど、障害はいつ起こるかわからないですもんね。はてなでは、障害のポストモーテムや障害対応の記録を取って社内に情報共有することをずっと続けているんですよね。誰かが止めようとか、しんどいからやめようと言うこともなくて、当然のようにできている。それが財産になっていると感じました。

この取り組みは主に定性的な情報共有でしたが、こうして可視化してみることで、障害対応の課題や改善点のヒントを見つけていくというのはいい取り組み。さらに広めたいですね。ずっと見ていたいけど、ずっと見るほどデータがあったら、ちょっと嫌かな(笑)。
SLOの改善というテーマではどんなことをしようとしているのですか。
例えば障害が頻繁に発生しているシステムコンポーネントがあったら、そのシステムコンポーネントでSLOがきちんと定義されているかを見ていく。つまり、定量的なデータから、SLOのカバレッジを広げる方向性に繋げていきたいと思っています。SLOをどのように設計していくかについても、「数字で見る障害対応」から派生して考えているところです。
SLOのカバレッジは、SLOがシステムの要点をちゃんとカバーできて、システムの障害が起きやすい部分であったり、ビジネス的に重要な部分が表現できていることですよね。障害対応やSLO周りの知見を広めていくいい方法って何かありますか?
Mackerelチームでやっているのは、ポストモーテム読書会ですね。僕はSREとして入社して社歴が浅いということもあり、Mackerelのサービスがどんなアーキテクチャで動いていているのかなど、Mackerelの中を解像度高く理解する必要があったんですね。そのキャッチアップにもポストモーテムはいい題材でした。
ポストモーテムを読んで実際の疑問点などを書き出して知識をキャッチアップしていく会などもやっていました。
僕はブログチームに異動したときに、システムを把握するためにブログチームのインフラ周りのSlackチャンネルを見て、誰がどんな立場でそれぞれどういう発言をしているのかをキャッチアップとして使っていたんですね。それを省力的にやれるのがポストモーテム読書会だなと思いました。
開発チームのエンジニアとインフラ担当が、月1回の頻度で開発状況や障害対策を共有し合うPWG(Performance Working Group)と呼ばれる会があるので、僕はそういうところから解像度を上げていってるかんじですね。
はてなのSREとして一緒に働きたいのはどんな人?
最後に今後どんな人と一緒に働きたいか、ひと言ずつコメントをお願いします。
ひと言でいうと、more betterを追求できるような人ですね。はてなのEmbedded SREの役割やミッションで重要なのは、一定の信頼性のもとで開発速度を最大化すること。そのトレードオフはそのプロダクトや開発チームの状況次第で求められることが変わるので、今はこの動きでいいんだけど、数カ月したらその動きは最適じゃなくなっている可能性もある。
つまり、今の時点でのモアベタ―をどんどん追求していく必要があるんですね。それはチームとしての動きもそうですけど、はてなの技術的な部分でも細部を含めてこだわり抜けるエンジニアであれば、SREとして一緒にプロダクトを良くしていくという観点でも一緒に働きたいなと思います。
Embedded SREは特にそうなんですけど、SREはアプリケーションエンジニアやインフラエンジニアなど、他の職種と一緒に仕事をすることが前提としてあります。彼らが何を考えてるのか、プロダクト全体の課題に対して自分は何ができるか、いろんなところからボトルネックを探して解決できないか探せる人が活躍できるんじゃないかと思います。
僕は「楽をしたい」と思ってる人と働きたいです。だから自動化したり、壊れてるところにすぐ気づけるような環境を作れる人と一緒に仕事したいですね。
標準化会の取り組みを見ていて思うのは、事業ドメインに特化することになるアプリケーションエンジニアと違い、SREはより抽象化された課題としてサービスやシステムに向き合うことになる。だからこそ、さまざまなサービスを展開しているはてなにおいても、チームを越えてコードやノウハウをダイレクトに共有できるんだと思います。いろいろなサービスを通じて、システムの課題に取り組み、仕組みで解決していける人には面白い組織なんじゃないかな、と思います。


